Tokenizations¶
This page details the tokenizations featured by MidiTok. They inherit from miditok.MusicTokenizer, see the documentation for learn to use the common methods. For each of them, the token equivalent of the lead sheet below is showed.

REMI¶

- class miditok.REMI(*args, **kwargs)¶
Bases:
MusicTokenizerREMI (Revamped MIDI) tokenizer.
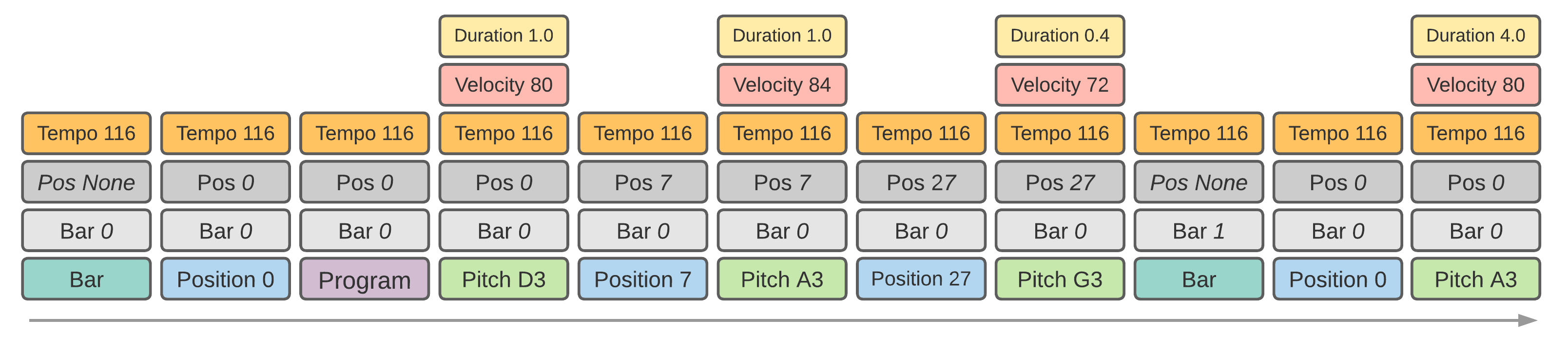
Introduced with the Pop Music Transformer (Huang and Yang), REMI represents notes as successions of Pitch, Velocity and Duration tokens, and time with Bar and Position tokens. A Bar token indicate that a new bar is beginning, and Position the current position within the current bar. The number of positions is determined by the
beat_resargument, the maximum value will be used as resolution. With the Program and TimeSignature additional tokens enables, this class is equivalent to REMI+. REMI+ is an extended version of REMI (Huang and Yang) for general multi-track, multi-signature symbolic music sequences, introduced in FIGARO (Rütte et al.), which handle multiple instruments by adding Program tokens before the Pitch ones.Note: in the original paper, the tempo information is represented as the succession of two token types: a TempoClass indicating if the tempo is fast or slow, and a TempoValue indicating its value. MidiTok only uses one Tempo token for its value (see Additional tokens). Note: When decoding multiple token sequences (of multiple tracks), i.e. when config.use_programs is False, only the tempos and time signatures of the first sequence will be decoded for the whole music.
- Parameters:
tokenizer_config – the tokenizer’s configuration, as a
miditok.classes.TokenizerConfigobject. REMI accepts additional_params for tokenizer configuration: | - max_bar_embedding (desciption below); | - use_bar_end_tokens – if set will add Bar_End tokens at the end of each Bar; | - add_trailing_bars – will add tokens for trailing empty Bars, if they are present in source symbolic music data. Applicable to REMI. This flag is very useful in applications where we need bijection between Bars is source and tokenized representations, same lengths, anacrusis detection etc. False by default, thus trailing bars are omitted.max_bar_embedding – Maximum number of bars (“Bar_0”, “Bar_1”,…, “Bar_{num_bars-1}”). If None passed, creates “Bar_None” token only in vocabulary for Bar token. Has less priority than setting this parameter via TokenizerConfig additional_params
params – path to a tokenizer config file. This will override other arguments and load the tokenizer based on the config file. This is particularly useful if the tokenizer learned Byte Pair Encoding. (default: None)
REMIPlus¶
REMI+ is an extended version of REMI (Huang and Yang) for general multi-track, multi-signature symbolic music sequences, introduced in FIGARO (Rütte et al.), which handles multiple instruments by adding Program tokens before the Pitch ones.
You can get the REMI+ tokenization by using the REMI tokenizer with config.use_programs, config.one_token_stream_for_programs and config.use_time_signatures enabled.
MIDI-Like¶

- class miditok.MIDILike(*args, **kwargs)¶
Bases:
MusicTokenizerMIDI-Like tokenizer.
Introduced in This time with feeling (Oore et al.) and later used with Music Transformer (Huang et al.) and MT3 (Gardner et al.), this tokenization converts music files to MIDI messages (NoteOn, NoteOff, TimeShift…) to tokens, hence the name “MIDI-Like”.
MIDILikedecode tokens following a FIFO (First In First Out) logic. When decoding tokens, you can limit the duration of the created notes by setting amax_durationentry in the tokenizer’s config (config.additional_params["max_duration"]) to be given as a tuple of three integers following(num_beats, num_frames, res_frames), the resolutions being in the frames per beat. If you specifyuse_programsasTruein the config file, the tokenizer will addProgramtokens before eachPitchtokens to specify its instrument, and will treat all tracks as a single stream of tokens.Note: as
MIDILikeuses TimeShifts events to move the time from note to note, it could be unsuited for tracks with long pauses. In such case, the maximum TimeShift value will be used. Also, theMIDILiketokenizer might alter the durations of overlapping notes. If two notes of the same instrument with the same pitch are overlapping, i.e. a first one is still being played when a second one is also played, the offset time of the first will be set to the onset time of the second. This is done to prevent unwanted duration alterations that could happen in such case, as theNoteOfftoken associated to the first note will also end the second one. Note: When decoding multiple token sequences (of multiple tracks), i.e. whenconfig.use_programsis False, only the tempos and time signatures of the first sequence will be decoded for the whole music.
TSD¶

- class miditok.TSD(*args, **kwargs)¶
Bases:
MusicTokenizerTSD (Time Shift Duration) tokenizer.
It is similar to MIDI-Like but uses explicit Duration tokens to represent note durations, which have showed better results than with *NoteOff* tokens. If you specify
use_programsasTruein the config file, the tokenizer will add Program tokens before each Pitch tokens to specify its instrument, and will treat all tracks as a single stream of tokens.Note: as
TSDuses TimeShifts events to move the time from note to note, it can be unsuited for tracks with pauses longer than the maximum TimeShift value. In such cases, the maximum TimeShift value will be used. Note: When decoding multiple token sequences (of multiple tracks), i.e. whenconfig.use_programsis False, only the tempos and time signatures of the first sequence will be decoded for the whole music.
Structured¶

- class miditok.Structured(*args, **kwargs)¶
Bases:
MusicTokenizerStructured tokenizer, with a recurrent token type succession.
Introduced with the Piano Inpainting Application, it is similar to TSD but is based on a consistent token type successions. Token types always follow the same pattern: Pitch -> Velocity -> Duration -> TimeShift. The latter is set to 0 for simultaneous notes. To keep this property, no additional token can be inserted in MidiTok’s implementation, except Program that can optionally be added preceding
Pitchtokens. If you specifyuse_programsasTruein the config file, the tokenizer will add Program tokens before each Pitch tokens to specify its instrument, and will treat all tracks as a single stream of tokens.Note: as
Structureduses TimeShifts events to move the time from note to note, it can be unsuited for tracks with pauses longer than the maximum TimeShift value. In such cases, the maximum TimeShift value will be used.
CPWord¶

- class miditok.CPWord(*args, **kwargs)¶
Bases:
MusicTokenizerCompound Word tokenizer.
Introduced with the Compound Word Transformer (Hsiao et al.), this tokenization is similar to REMI but uses embedding pooling operations to reduce the overall sequence length: note tokens (Pitch, Velocity and Duration) are first independently converted to embeddings which are then merged (pooled) into a single one. Each compound token will be a list of the form (index: Token type):
0: Family;
1: Bar/Position;
2: Pitch;
(3: Velocity);
(4: Duration);
(+ Optional) Program: associated with notes (pitch/velocity/duration) or chords;
(+ Optional) Chord: chords occurring with position tokens;
(+ Optional) Rest: rest acting as a TimeShift token;
(+ Optional) Tempo: occurring with position tokens;
(+ Optional) TimeSig: occurring with bar tokens.
The output hidden states of the model will then be fed to several output layers (one per token type). This means that the training requires to add multiple losses. For generation, the decoding implies sample from several distributions, which can be very delicate. Hence, we do not recommend this tokenization for generation with small models. Note: When decoding multiple token sequences (of multiple tracks), i.e. when
config.use_programsis False, only the tempos and time signatures of the first sequence will be decoded for the whole music.
Octuple¶

- class miditok.Octuple(*args, **kwargs)¶
Bases:
MusicTokenizerOctuple tokenizer.
Introduced with MusicBert (Zeng et al.), the idea of Octuple is to use embedding pooling so that each pooled embedding represents a single note. Tokens (Pitch, Velocity…) are first independently converted to embeddings which are then merged (pooled) into a single one. Each pooled token will be a list of the form (index: Token type):
0: Pitch/PitchDrum;
1: Position;
2: Bar;
(+ Optional) Velocity;
(+ Optional) Duration;
(+ Optional) Program;
(+ Optional) Tempo;
(+ Optional) TimeSignature.
Its considerably reduces the sequence lengths, while handling multitrack. The output hidden states of the model will then be fed to several output layers (one per token type). This means that the training requires to add multiple losses. For generation, the decoding implies sample from several distributions, which can be very delicate. Hence, we do not recommend this tokenization for generation with small models.
Notes:
- As the time signature is carried simultaneously with the note tokens, if a Time
Signature change occurs and that the following bar do not contain any note, the time will be shifted by one or multiple bars depending on the previous time signature numerator and time gap between the last and current note. Octuple cannot represent time signature accurately, hence some unavoidable errors of conversion can happen. For this reason, Octuple is implemented with Time Signature but tested without.
Tokens are first sorted by time, then track, then pitch values.
Tracks with the same Program will be merged.
- When decoding multiple token sequences (of multiple tracks), i.e. when
config.use_programs is False, only the tempos and time signatures of the first sequence will be decoded for the whole music.
MuMIDI¶
- class miditok.MuMIDI(*args, **kwargs)¶
Bases:
MusicTokenizerMuMIDI tokenizer.
Introduced with PopMAG (Ren et al.), this tokenization made for multitrack tasks and uses embedding pooling. Time is represented with Bar and Position tokens. The key idea of MuMIDI is to represent all tracks in a single token sequence. At each time step, Track tokens preceding note tokens indicate their track. MuMIDI also include a “built-in” and learned positional encoding. As in the original paper, the pitches of drums are distinct from those of all other instruments. Each pooled token will be a list of the form (index: Token type):
0: Pitch / PitchDrum / Position / Bar / Program / (Chord) / (Rest);
1: BarPosEnc;
2: PositionPosEnc;
(-3 / 3: Tempo);
-2: Velocity;
-1: Duration.
The output hidden states of the model will then be fed to several output layers (one per token type). This means that the training requires to add multiple losses. For generation, the decoding implies sample from several distributions, which can be very delicate. Hence, we do not recommend this tokenization for generation with small models.
Notes:
Tokens are first sorted by time, then track, then pitch values.
Tracks with the same Program will be merged.
MMM¶
- class miditok.MMM(*args, **kwargs)¶
Bases:
MusicTokenizerMMM tokenizer.
Standing for Multi-Track Music Machine, MMM is a multitrack tokenization primarily designed for music inpainting and infilling. Tracks are tokenized independently and concatenated into a single token sequence.
Bar_Filltokens are used to specify the bars to fill (or inpaint, or rewrite), the new tokens are then autoregressively generated. Note that this implementation represents note durations withDurationtokens instead of theNoteOffstrategy of the original paper. The reason being thatNoteOfftokens perform poorer for generation with causal models.Add a
density_bins_maxentry in the config, mapping to a tuple specifying the number of density bins, and the maximum density in notes per beat to consider. (default: (10, 20))Note: When decoding tokens with tempos, only the tempos of the first track will be decoded.
- Parameters:
tokenizer_config – the tokenizer’s configuration, as a
miditok.TokenizerConfigobject.params – path to a tokenizer config file. This will override other arguments and load the tokenizer based on the config file. This is particularly useful if the tokenizer learned Byte Pair Encoding. (default: None)
PerTok¶
- class miditok.PerTok(*args, **kwargs)¶
Bases:
MusicTokenizerPerTok: Performance Tokenizer.
Created by Lemonaide https://www.lemonaide.ai/
Designed to capture the full spectrum of rhythmic values (16ths, 32nds, various denominations of triplets/etc.) in addition to velocity and microtiming performance characteristics. It aims to achieve this while minimizing both vocabulary size and sequence length.
Notes are encoded by 2-5 tokens:
TimeShift;
Pitch;
Velocity (optional);
MicroTiming (optional);
Duration (optional).
Timeshift tokens are expressed as the nearest quantized value based upon beat_res parameters. The microtiming shift is then characterized as the remainder from this quantized value. Timeshift and MicroTiming are represented in the full ticks-per-quarter (tpq) resolution, e.g. 480 tpq.
Additionally, Bar tokens are inserted at the start of each new measure. This helps further reduce seq. length and potentially reduces the timing drift models can develop at longer seq. lengths.
New TokenizerConfig Options:
beat_res: now allows multiple, overlapping values;
ticks_per_quarter: resolution of the MIDI timing data;
use_microtiming: inclusion of MicroTiming tokens;
max_microtiming_shift: float value of the farthest distance of MicroTiming shifts;
num_microtiming_bins: total number of MicroTiming tokens.
Example Tokenizer Config:
TOKENIZER_PARAMS = { "pitch_range": (21, 109), "beat_res": {(0, 4): 4, (0, 4): 3}, "special_tokens": ["PAD", "BOS", "EOS", "MASK"], "use_chords": False, "use_rests": False, "use_tempos": False, "use_time_signatures": True, "use_programs": False, "use_microtiming": True, "ticks_per_quarter": 320, "max_microtiming_shift": 0.125, "num_microtiming_bins": 30, "use_position_toks": true } config = TokenizerConfig(**TOKENIZER_PARAMS)
Create yours¶
You can easily create your own tokenizer and benefit from the MidiTok framework. Just create a class inheriting from miditok.MusicTokenizer, and override:
miditok.MusicTokenizer._add_time_events()to create time events from global and track events;miditok.MusicTokenizer._tokens_to_score()to decode tokens into aScoreobject;miditok.MusicTokenizer._create_vocabulary()to create the tokenizer’s vocabulary;miditok.MusicTokenizer._create_token_types_graph()to create the possible token types successions (used for eval only).
If needed, you can override the methods:
miditok.MusicTokenizer._score_to_tokens()the main method calling specific tokenization methods;miditok.MusicTokenizer._create_track_events()to include special track events;miditok.MusicTokenizer._create_global_events()to include special global events.
If you think people can benefit from it, feel free to send a pull request on Github.